項目反応理論 (IRT)
近年,項目反応理論 (もしくは項目応答理論) という言葉に触れることが増えています。項目反応理論 (Item Response Theory: IRT) はテスト理論の1つで,古典的テスト理論のあとに出てきた新しい理論です。異なるテスト間の得点 (能力値) を比較できる,受検者間で問題が異なってもよい,コンピュータと相性がよい (Computer Based Testing: CBT, Cpmputer Adaptive Testing: CAT) などの特質があり注目されていますが,適切に運用するためには注意しなければならない点もあります。ここでは項目反応理論の概要について説明します。
合計得点の問題点
項目反応理論について説明する前に,テスト得点としてよく用いられる合計得点の問題点について,まず整理しておきます。
問題の難易度の影響を受ける
テストの得点は多くの場合,正答した項目に対する配点を合計した合計得点として算出されます。また,テストに含まれる項目は,テスト実施前にセット (固定) されます。それゆえ,どのような項目をテストに含めるかによって,各受検者の合計得点は異なってきます。易しい問題が多ければ,多くの受検者が高得点になりますし,難しい問題が多ければ,多くの受検者が低得点になります。
このように,合計得点を用いた場合は,テスト得点は受検者の能力と問題の難易度の両方の影響を受け,たとえ高得点でも,能力が高いのか問題が易しかったのか,区別できないという問題があります。
問題の配点の影響を受ける
項目ごとに配点を変えると,配点の大きい項目に正答したか否かが,より合計得点に影響するようになります。難しい問題に大きい配点を与えているテストをよく見かけますが,難しい問題に正答できるのは能力の高い一部の受検者だけです。そうすると合計得点の分布は,能力の高い一部の受検者だけの得点が高くなり,他の多くの受検者の得点は低いところに押しとどめられるようになります。
テストの目的がひと握りのエリートを選抜することだとしたら,この配点は有効ですが,多くの受検者の能力を適正に測ることが目的だとしたら,この配点不適切な配点となります。難しい問題の配点を高くして多くの受検者の能力を適正に測るには,部分点を付与する必要があります。近年,思考力を問うなどと言って,正しいものをすべて選べという複数選択式問題を出題し,完全正答のみを正答,それ以外をすべて誤答とする 問題が見受けられますが,多くの受検者の能力を適正に評価するという観点からはお勧めできません。半分は理解しているなら,それに部分点を与え得点に反映したほうが,受検者の能力をより精確に測ることができます。
一般に,各受検者の能力をより精確に測定するには,易しい問題から難しい問題まで幅広い問題を用いる,ボリュームゾーンの問題をより多くする,すべての問題の配点を等しくする,などの要件を満たすようにテストを構成するのがよいとされています。そうすれば,どの能力層の得点も押しとどめられることなく広く分布し,個々の受検者の能力をより精確に捉えることができるようになります。
テスト間の得点の比較ができない
テストを構成する項目が事前に固定され,その固定された項目の難易度にテスト得点が影響されるとなると,異なるテスト間の得点を比較しても意味をなしません。テストに含まれる項目が異なるということは,違う物差しを用いているということです。難易度が異なるということは,目盛り設定が違うということです。なので,異なるテスト間の得点をそのまま比較することはできないのです。 (等化・尺度化を行えば比較することができます。)
たとえば,国語のテストと家庭科のテストの得点を比較しても意味がありません。一見,得点の高い方が得意と思いがちですが,国語と家庭科を,身長(cm)と血圧(mmHg)に置き換えて考えてみたら,比較のしようがないことが分かるでしょう。
同様に,同じ科目のテストで,中間60点,期末80点だから能力が上がったと主張するのも適切ではありません。同じ科目だとしても,出題範囲 (物差し) が違ううえ,難易度 (目盛り設定) も異なるからです。中間が易しく期末が難しいテストだったら,能力は上がっていても得点は下がるかもしれません。
偏差値
合計得点の問題点を回避するものの1つとして偏差値があります。偏差値を用いると,受検者集団における各受検者の相対的位置を把握することができます。偏差値は以下の式で求められます。
得点分布が正規分布だとした場合の,偏差値と平均 \( (\mu) \) および標準偏差 \( (\sigma) \) との関係,また,一定の範囲に何パーセントの受検者がいるかを示した図を以下に示します。この図を見ると,偏差値50はちょうど真ん中 (50%),偏差値55は上位約30%,偏差値60は上位約16%,偏差値65は上位約7%のところに位置していることが分かります。

偏差値により,自分は平均よりどれくらい離れた位置にいるのかを知ることができます。科目ごとに偏差値を計算すれば,各科目における相対位置が分かるので,受検者集団の中で,自分が上位にいる科目,下位にいる科目が分かります。また,中間と期末の偏差値を比較することにより,受検者集団の中での位置の変化を知ることができます。
能力の変化を捉えるのに適さない
偏差値を用いれば,得点の相互比較はある程度可能になります。しかし,そこには「受検者集団の中で」という限定がつきます。ある個人が,全体的に能力の高い集団に入れば偏差値は低くなりますし,全体的に能力の低い集団に入れば偏差値は高くなります。偏差値は当該受検者の能力を反映する値ですが,受検者集団がどのような集団であるかによって,同じ個人でも値が変わってしまうのです。
また,中間テストと期末テストの間で個人の能力が上昇していたとしても,集団全体の能力も同様に上昇していれば,中間と期末の偏差値は変わりません。偏差値は受検者集団の中での相対的な位置を表す値なので,全体が上昇すれば,各個人の相対位置は変わらないからです。これが,偏差値では児童生徒の伸びを捉えられないと批判される理由になります。
項目反応理論とは
項目反応理論 (Item Response Theory: IRT) は,合計得点の問題点を解決するために,項目の難易度などの項目特性と,各受検者の能力を分離して考え,共通尺度上でのテストの構築と実施を支えるテスト理論で,項目応答理論とも呼ばれます。
項目反応理論でどのように得点を求めるかを簡単に説明すると次のようになります。まず,各項目の困難度や識別力などの項目特性と受検者の能力から,ある能力値の受検者が各項目に正答する確率を項目ごとに考えます。そして,各受検者の正誤データがもっとも得られやすい能力値を推定して,その受検者の得点とします。
項目特性と受検者の能力が分離されているので,各受検者の能力値は項目に影響されません。つまり,同じ能力を測っているテストであれば,異なるテスト間の能力値 (得点) を比較することが可能です。年に複数回実施されるテストの得点を相互比較することもできますし,各受検者の能力の変化を捉えることも可能になります。
求められる要件
上述したように項目反応理論は,合計得点を用いたテストの問題点を解決する有効な手法です。しかし,実際に用いるためには,いくつかの (厳しい) 要件を満たす必要があります。ここではそれらについて説明します。
大規模データが必要
項目の困難度や識別力などを表す値 (項目特性値) を適切に推定するためには,非常に多くのデータが必要で,最低でも千人規模の受検者からデータを集めることが求められます。また,各受検者の能力値を推定するには相応の項目数が必要で,20項目以上は必要と言われることもあります。このように項目反応理論では,1回1回の試験で大規模なデータを収集する必要があります。
項目を非開示にしなければならない
テスト実施時は,困難度や識別力などの項目特性値を推定する項目 (予備調査項目) と,受検者の能力値を推定する項目 (本試験項目) を混在させます。各項目がどちらのものかは受検者には知らせません。予備調査で項目特性値を推定した項目を,後日本試験項目として使用します。
しかし,項目の困難度や識別力は,項目 (問題) を公開すると変化してしまいます。受験産業などが利用したり,過去問題集に掲載されたりして,受検者が対策を立ててしまうからです。それゆえ,項目反応理論を用いたテストでは,項目を非開示にしなければなりません。ですが,重要 (ハイステークス) な試験になるほど,また受検者が多くなるほど,問題漏洩の可能性が高くなり,テストの実施体制そのものが脅かされるようになります。
項目プールの構築
テストでは,能力の低い層から高い層まで,幅広い受検者の能力を適正に測定することが求められます。それゆえ,易しい項目から難しい項目まで,多量の項目をストックしておく必要があります。また,項目を繰り返し使用していると,項目の困難度や識別力などの項目特性が変化してしまうこもあります。その場合は,古い問題を破棄し,新しい問題と入れ替えます。
テストを円滑かつ持続的に実施するには,どのような領域に,どのような特性を持った項目が,何問くらい蓄積されているか,前に使用したのはいつか,どの項目と内容が重なっているか,どの項目と同時に用いてはならないか,などの情報を管理する必要があります。そのために「項目プール (項目バンク)」(Item Pool, Item Bank) というものを構築します。要は,項目と必要な情報を搭載したデータベースです。試験の規模にもよりますが,実際の項目プールでは数百~数千個の項目を搭載していることが多いようです。
項目間に依存関係があってはいけない
項目反応理論では,各受検者において,それぞれの項目に正答する (または誤答する) 確率は互いに独立であると仮定します。専門的には「局所独立性の仮定」と言います。たとえば,前の問題の答えを使って次の問題を解く問題は,前の問題に誤答したら必然的に次の問題も誤答になってしまうので,要件を満たしません。前の問題につまずいても次の問題の正誤にはまったく影響しないという,項目間に依存関係のないテストの構成を項目反応理論は念頭においています。1つの題材に対して複数の問題を設定する大門形式の問題も,局所独立性が損なわれる場合がありますので注意が必要です。
なお,局所独立性の仮定は,そのテストで測っている能力は一次元であるという一次元性の仮定でもあります。各項目に正答するか誤答するかは能力だけによって決まり,能力を固定してしまえば,それ以外のものは影響しないという仮定になっているからです。
基本的に多枝選択式問題
項目反応理論を用いたテストの多くは,データとして2値型データ (正答=1,それ以外= 0) を利用しています。多値型データ (正答=2,部分正答=1,それ以外=0 など) を利用する項目反応理論もありますが,計算が複雑になり,さらに多くのデータが必要になります。それゆえ多くの場合,項目反応理論を用いたテストは,データ収集や採点が容易かつ正確な,択一式の多枝選択式問題で構成されます。
<先頭へ戻る> <テスト研究のページへ戻る>項目特性曲線
項目反応理論では,各項目の困難度や識別力などの項目特性と,受検者の能力から,各受検者がその項目に正答する確率を考え,受検者の能力値 (得点) を推定します。ここではその仕組みについて,もう少し詳しく解説します。なお,各項目の得点は,正答=1,誤答=0 という2値型データであるとします。
項目特性関数
ある能力 (たとえば数学) を測定する項目が3つあり,1つめは易しい項目,2つめは中程度の項目,3つめは難しい項目とします。ここで,横軸に受検者の能力,縦軸にその項目に正答する確率を示す図を考えたら,これら3項目の正答確率を表す図 (曲線) は,それぞれどのようなかたちになるでしょうか?
おそらく,易しい項目は能力の低い受検者でも正答できますから,正答確率を表す曲線は下図の①のようになるでしょう (能力値が-2の受検者でも正答確率は0.5ある)。反対に,難しい項目は能力の高い受検者でもなかなか正答できませんから,正答確率を表す曲線は③のようになると考えられます (能力値が+2でも正答確率は0.5しかない)。中程度の項目の曲線は,①と③の間の②のようになります。
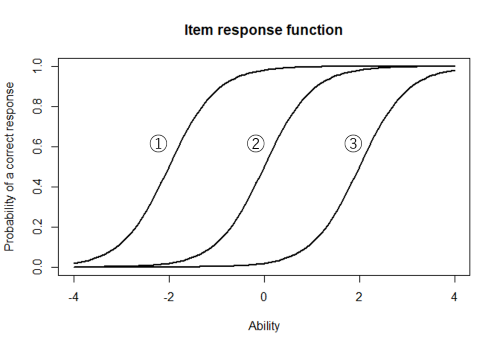
このように,受検者の能力値に項目の正答確率を対応させる曲線を項目特性曲線 (item characteristic curve) と言い,その曲線を表す関数を項目特性関数 (または項目反応関数) と言います。この項目特性関数のかたちは,困難度や識別力など項目の特性を表す値 (パラメタ) によって決められます。困難度は曲線の位置,識別力は曲線の傾きを規定します。
いま,項目 \(j\) の困難度を \( b_j \) ,識別力を \(a_j \) とし,受検者の能力を \( \theta \) で表すことにします。項目特性関数として2パラメタロジスティックモデルというものを用いる場合は,各受検者が項目 \(j\) に正答する確率 \(P_2 \) に次の関数 \(P_j(\theta) \) をあてはめます。
\(P_j(\theta) \) は \( \theta \) の関数で,①~③の曲線 (ロジスティック曲線) を決定するものです。\( D \) は定数で,Rのirtoysパッケージやmirtパッケージでは \(D=1.0\) としています。なお,\( D=1.7\) または \(1.702\) とすると,同じ項目パラメタの値を持つ2パラメタロジスティック曲線と正規累積曲線がほぼ一致するので,BILOG-MGなどではこちらの値を採用しています。識別力 \(a_j\) が正の値であればロジスティック関数は \( \theta \) に関して単調増加関数となり,能力値が高いほど正答確率は高くなります。
2パラロジスティックモデル以外の項目特性関数を用いることもあります。1パラメタロジスティックモデルは,各項目の識別力は同じであるとし,項目特性を困難度だけで捉えます。項目特性関数は次のようになります。
図の①~③の項目特性曲線は傾きが同じであり,識別力パラメタ \( a_j \) の値が共通していますので (\( a_j =1 \)),1パラメタロジスティックモデルの項目特性関数を表しています。なお,1パラメタロジスティックモデルは,ラッシュモデル (Rasch model) と言われるモデルと数式が同等になります。
3パラメタロジスティックモデルというものもあります。3パラメタロジスティックモデルは,困難度,識別力に加え,あて推量 (random guessing) を考慮するモデルです。項目 \( j \) のあて推量を表すパラメタを \( c_j \) とすると,項目特性関数は次のようになります。
どのモデルを用いても受検者の能力値 \(\theta\) を推定できますが,1パラメタモデルはヨーロッパやオーストラリア,2パラメタモデルは日本,3パラメタモデルはアメリカのテストでよく用いられます。
困難度
図の①~③の曲線は,問題の難しさによって位置が異なっています。困難度 (difficulty) は項目特性曲線の位置を規定する値で,項目特性曲線の傾きがもっとも大きいところの \( \theta \) の値です。1パラメタ及び2パラメタロジスティックモデルの場合,困難度は正答確率が 0.5 になるところの能力値になります。①~③の項目の困難度の値は,項目①が-2,②が0,③が+2で,困難度の値が大きいほど難しい問題であることを表します。
困難度は,項目分析における正答率に対応する指標ですが,正答率は値が大きいほど易しい問題であることを表すので注意が必要です。
識別力
下図の項目④~⑥の項目特性曲線は,困難度は同じ値 (\( b_j = 0 \)) ですが,曲線の傾きが異なっています。項目④は,能力値がちょうど困難度レベル (\(\theta = 0) \) で正答確率が大きく変化している項目です。一方,項目⑥は \( \theta = 0 \) 付近で正答確率はあまり変化せず,能力値の広い範囲で正答確率は緩やかに変化しています。項目⑤は \( \theta = 0 \) 付近での正答確率の変化が④と⑥の間の項目です。このように,項目特性曲線の傾きは,能力値がちょうど困難度レベルの受検者の正答確率がどの程度変化するかを表します。そこで,項目特性曲線の傾きに対応する値をその項目の識別力 (discrimination) とします。識別力は,能力の低い受検者と能力の高い受検者を,どれくらいよく区別できるかを表す指標ということになります。
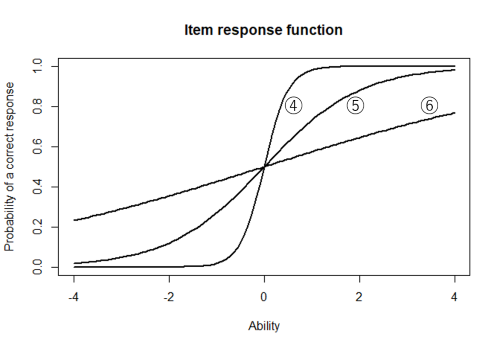
項目④は,能力値が0より低い受検者と能力値が0より高い受検者で正答確率が大きく変わるので,識別力の大きい項目です。これに対し項目⑥は,能力の低い受検者と能力の高い受検者で正答率はそれほど変わりませんから,識別力の小さい項目です。
識別力は,項目特性曲線において,能力値=困難度 となるところの曲線の傾きに対応します。すなわち,当該の項目特性曲線において傾きが最大となるところの能力値を困難度,傾きを識別力としている訳です。図の各項目の識別力の値は,項目④が +4,⑤が +1,⑥が +0.3 となっています。通常の項目では能力が高いほど正答確率は大きくなると考えられますから,一般に識別力は正の値にします。
項目④~⑥は,識別力は異なりますが困難度の値が共通しているので,識別力 (だけ) を異にする1パラメタロジスティックモデルと捉えることもできます。しかし,実際のテストにおいて項目の困難度がみな同じであるということはまずないので,このようなモデルは立てません。通常,1パラメタロジスティックモデルと言う場合は,困難度 (だけ) を異にするモデルを考えます。
なお,項目分析において識別力は,D指標やI-T相関係数などで表され,やはり能力 (合計得点) の低い受検者と高い受検者をどれくらい区別できるかを示します。
項目パラメタの推定
上の項目①~③の3項目からなるテストがあるとします。これらの項目に対し,能力値が-2くらいの受検者は,①の項目には正答できても②,③の項目に正答できる確率は低いので,正誤パターンは (1,0,0) のようになると推察されます。一方,能力値が+3程度の受検者は,どの項目にも正答できそうですから,正誤パターンは (1,1,1) のようになりそうです。また,能力値が0近辺の受検者は,①に正答,③に誤答は予想できるとして,②に正答するか誤答するかは五分五分なので,正誤パターンとしては (1,1,0) や (1,0,0) などが考えられます。
このように,困難度や識別力などの項目パラメタの値が分かっている項目を使ってテストを行えば,それらの項目に対する正誤パターンから各受検者の能力値を推定することができます。そこで項目反応理論では,まず項目パラメタの値を推定します。
能力値が \(\theta\) の受検者 \(i\) が項目 \(j\) に正答する確率 \(p_{ij}\) を \(P_j(\theta)\),誤答する確率 \(1-p_{ij}\) を \(~1-P_j(\theta)\) とします。\(P_j(\theta)\) は \(\theta\) の関数です。また,受検者 \(i\) が項目 \(j\) に正答したら \(u_{ij}=1\),誤答したら \(u_{ij}=0\) のように正誤状態を表す記号 \(u_{ij}\) を考えます。すると,受検者 \(i\) の正誤パターン \(u_i = (u_{i1}, u_{i2}, u_{i3})\) が \((1,1,0)\)となる確率 \(p(u_i=(1,1,0))\) は,項目間に依存関係がなければ次のように計算することができます。
項目間に依存関係がないとは,前の項目への回答を使って次の項目に答えたりしないということです。項目反応理論ではこれを局所独立 (local independence) と言います。項目間に依存関係があり局所独立でない場合は,前の問題の正誤が次の問題の正誤に影響してしまいます。局所独立が仮定される場合は,ある正誤パターンが得られる確率は各項目の正誤が得られる確率の積になるということを,上の式は表しています。
念のため,項目数が \(n\) 個の場合の式も書いておきます。
なお,2パラメタロジスティックモデルを用いた場合,\(P_{j}(\theta)\) は次のようになります。
項目数が3個のとき,正誤パターンは全部で \(2^3=8\) 通りあります。具体的には,(0,0,0),(0,0,1), (0,1,0), (1,0,0), (0,1,1), (1,0,1), (1,1,0), (1,1,1) です。これらの正誤パターンを \(U_1, U_2, \cdots,U_8\) とすると,先ほどの受検者 \(i\) の正誤パターン \(u_{i}=(1,1,0)\) は,\(u_i =U_7\) ということになります。
さて,それぞれの正誤パターンが得られる確率を \(p(U_1), p(U_2), \cdots, p(U_8)\) とすると,\(N\) 名の受検者のうち各正誤パターンの人数が \(N_1, N_2, \cdots, N_8\) となる確率は,次の式のようになります。
ただし,
です。これは多項分布と言われる確率分布です。項目数が \(n\) 個の場合は,
となります。
\(p(U_p)\) は,能力値 \(\theta\) がある値であるときに正誤パターン \(U_p = (U_{p1}, U_{p2}, \cdots, U_{pn})\) が得られる確率を \(\theta\) について積分したもので,項目パラメタだけを含む式になります。\(\theta\) の確率分布を \(p(\theta)\) とすると,\(p(U_p)\) は次のようにして得られます。
\(p(U_p)\) が項目パラメタだけを含む式になりますから,\(p(N_1, N_2, \cdots, N_{2^n})\) も項目パラメタだけを含む式で表されます。よって,正誤パターンの人数が \(N_1, N_2, \cdots, N_8\) となる確率 \(p(N_1, N_2, \cdots, N_{2^n})\) を最大にするような項目パラメタの値を求めれば,それが項目パラメタの推定値となります。この方法は周辺最尤推定法 (marginal maximum likelihood method) と呼ばれます。\(\theta\) を積分して項目パラメタの値を求めるにあたってはコンピュータを利用した数値計算が用いられます。
解の不定性
実際の推定にあたっては,解の不定性をなくすために,\(\theta\) の平均と標準偏差の値を固定します。解の不定性とは,原点と単位を任意に取ることができるという性質で,以下の関係を満たすいかなる推定値 (\(\theta^*_i, b^*_j, a^*_j\)) も解になるというものです。
通常,\(\theta\) の確率分布 \(p(\theta)\) に標準正規分布を仮定し,平均 0,標準偏差 1 として,解の不定性の問題を回避します。
<先頭へ戻る> <テスト研究のページへ戻る>能力値の推定
困難度や識別力などの項目特性パラメタの値が分かっていれば,それらの項目に対する正誤パターンから各受検者の能力値を推定することができます。受検者 \(i\) において,項目パラメタの値が分かっている \(n\) 個の項目に対する正誤パターン \(u_i=(u_{i1}, u_{i2}, \cdots, u_{in})\) が得られる確率は,
です。よって,この確率を最大にするような \(\theta\) の値を求めれば,それが受検者 \(i\) の能力値 \(\theta_i\) の推定値になります。やはり,コンピュータを用いた数値計算によって値を計算します。
項目反応理論では正誤パターンを用いて能力値を推定するので,一般に合計得点が同じでも能力値は違う値になります。たとえば,項目④~⑥からなるテストに対する正誤パターンが (1,0,0),(0,1,0),(0,0,1) となるとき,合計得点はどれも1点ですが,能力値はそれぞれ, +0.4,-0.5,-1.5 と推定されます。これに対し,項目①~③の場合は,いずれのパターンでも能力値は -1.0 となります。項目①~③は識別力の値が同じであることから,このような結果になります。つまり,1パラメタロジスティックモデル (ラッシュモデル) を用いた場合は,合計得点と能力値は1対1に対応し,正誤パターンは能力値に影響しないということになります。
\(\theta\) の確率分布に標準正規分布を仮定するので,\(\theta\) の推定値は +0.4 や -1.5 のような値になります。しかし,値が小さくて分かりにくい,能力のレベルをイメージしにくい,能力値がマイナスというのは印象が良くないなどの理由で,実際のテストにおいては,能力値は \(\theta\) の値そのものではなく,一定数を掛けたり足したリして,適当な大きさの値に変換されたものが報告されます。
情報量
項目情報関数
項目①は能力値-2付近,②は0付近,③は+2付近の受検者をよく識別します。逆に考えると,項目①に正答するかしないかで能力値が-2より大きいか小さいか,②に正答するかしないかで能力値が0より大きいか小さいか,③に正答するかしないかで能力値が+2より大きいか小さいかをよく推定できることになります。つまり,項目①がもたらす情報量は能力値-2付近で大きく,同様に②は0付近,③は+2付近で情報量が大きいということです。
ある項目に正答するかしないかで,その項目が能力値の推定にもたらす情報の量を \(\theta\) の関数で表したものを項目情報関数 (item information function) と言います。2パラメタロジスティックモデルの場合,項目 \(j\) の項目情報関数 \(I_j(\theta)\) は次の式で定義されます。
項目①~③および項目④~⑥の項目情報関数をグラフで表すと下図のようになります。
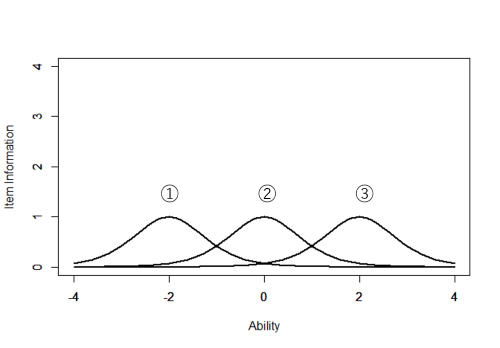
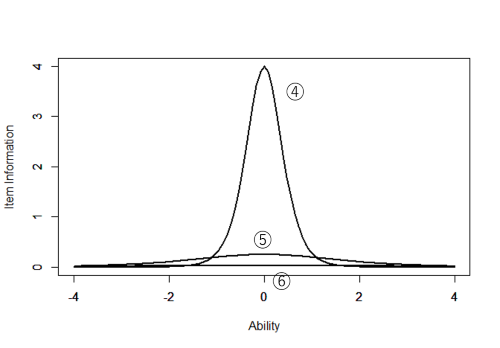
これらの項目情報関数を見ると,項目情報量はその項目の困難度のところで最大になり,識別力が大きいほど情報量が大きくなることがわかります。情報量が大きいということは,それだけ能力値の推定精確が高いということであり,反対に情報量が小さいということは,それだけ能力値の推定精度が低いことを表します。
テスト情報関数
テストに含まれる項目の項目情報関数を合計したものをテスト情報関数 (test information function) と言います。テスト情報関数 \(I(\theta)\) を求める式は次のようになります。
項目①~③および項目④~⑥からなるテストのテスト情報関数はそれぞれ次のようになります。
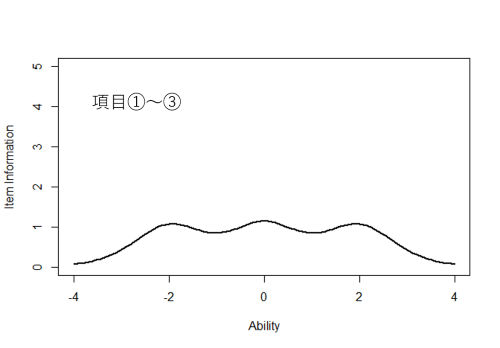
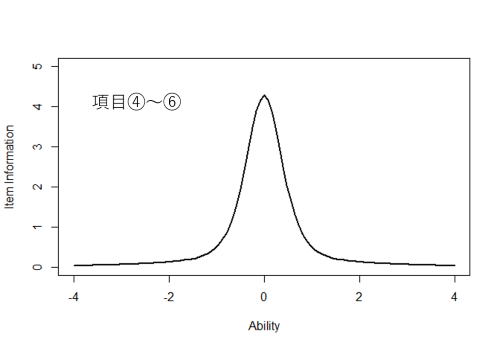
項目①~③からなるテストは,能力値が-2~+2あたりの受検者の能力を概ね一定の推定精度でまんべんなく推定できるのに対し,項目④~⑥からなるテストは,能力値が-0.5~ +0.5あたりの受検者の能力は高い精度で推定できるものの,-1以下もしくは+1以上になると推定精度がとても低くなっていることがわかります。
適応型テスト (Computer Adaptive Test: CAT) では,受検者ごとに,その受検者の能力値付近の項目を多く出題することによって,各受検者の能力値を高い精度で推定することができます。これに対し,項目を入れ替えられない固定型テストで,より多くの受検者の能力値を高い精度で推定するためには,困難度の低い (易しい) 項目から困難度の高い (難しい) 項目までを,一定の割合で含めることが必要になってきます。多くの場合,ボリュームゾーンである中困難度の項目を多めにします。
等化・尺度化
等化・尺度化とは
項目反応理論を用いれば異なるテスト間の能力値 (得点) を比較することも可能だと説明しました。テストに含まれる項目が異なるのにどうして能力値を比較できるのでしょうか?
能力値の推定のところで説明したように,各受検者の能力値は,困難度や識別力などの項目特性が分かっている項目に対する正誤パターンから推定されます。よって,項目の困難度や識別力が共通の尺度上にあり相互比較可能であれば,そこから推定される能力値もその共通の尺度上で定義され,たとえ項目が異なっていたとしても相互比較ができるようになります。要は,項目の困難度や識別力の値を共通の尺度上に乗せればよいのです。その手続きとして,等化や尺度化があります。
ひとことで言うと等化・尺度化は,複数のテストの得点を互いに比較可能にする共通の尺度を構成することです。同じ能力を測定する複数の同等のテストの能力値を比較可能にする場合を等化,学力の経年変化を捉えるなど難易度や内容が異なるテストの能力値を比較可能にする場合を (垂直) 尺度化と言います。
項目反応理論を用いなくても等化・尺度化はできる
テスト得点の等化・尺度化は,項目反応理論を用いなくても可能です。等パーセンタイル法などの手法を用いて,たとえばテストAの50点はテストBの55点に相当するというように,異なるテスト間の得点を対応づけ,一方の得点を他方の得点に変換して相互比較を可能にすることができます。
等パーセンタイル法
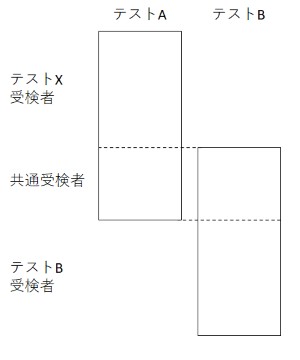
等パーセンタイル法用いて,テストAの得点をテストBの得点に変換する方法を紹介します。下図のように,テストAとテストBの両方のテストに回答する受検者が一定数いるようにします。2つのテストはほぼ同時期に実施します。このようなデータ収集計画を共通受検者デザインと言います。
共通受検者デザインにおいて両方のテストに回答した受検者のデータから,それぞれのテスト得点の累積度数曲線を作成します。この2つの累積度数曲線を比較し,テストAの得点 \(X\) の累積パーセントと同じ累積パーセントになるテストBの得点 \(B(X)\) を探せば,テストAの得点XをテストBの得点 \(B(X)\) に変換することができます。
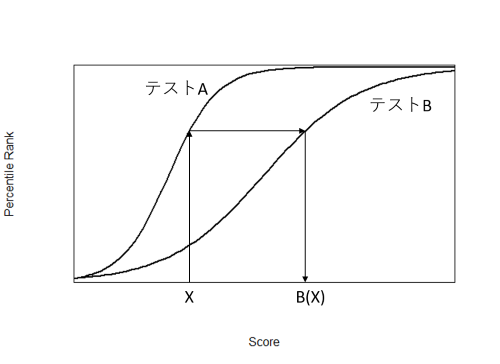
そのようにして得られたテストAの得点とテストBの得点の対応関係を用いて,テストAしか受検しなかった受検者の得点をテストBの得点に変換すれば,テストAを受けた受検者とテストBを受けた受検者の得点を,テストB上の得点で相互比較することができるようになります。同じ原理で,テストBの得点をテストAの得点に変換し,テストA上の得点で相互比較することも可能です。
なお,共通受検者デザインを用いる場合は,共通受検者の能力分布に偏りがないこと,低層から高層まで広く分布していることが求められます。等化・尺度化を適切に行うためには千名規模の共通受検者が必要になります。
項目反応理論を用いた等化
項目反応理論の適用が難しい場合には,等パーセンタイル法などを用いてテスト得点を等化・尺度化をすることは有効ですが,等化・尺度化されるのは当該のテストについてのみとなり,テストが変われば等化・尺度化を1からからやり直す必要があります。一方,項目反応理論を用いた場合は,各項目の困難度や識別力,受検者の能力値を共通尺度上の値に変換することにより,等化・尺度化された任意のテストの能力値を相互比較することが可能になります。項目反応理論において等化・尺度化は,項目の困難度や識別力,受検者の能力値を共通尺度上の値に変換することと言えます。以下に,項目反応理論を用いた等化の方法をいくつか紹介します。
共通受検者法
テストAとテストBの両方のテストに回答する受検者が一定数いる共通受検者デザインを組みます。
テストAデータを用いて,テストA項目の項目パラメタ \(b^A_j, a^A_j\) と,テストA受検者の能力値 \( \theta^A_i \),テストBデータを用いて,テストB項目の項目パラメタ \(b^B_j, a^B_j\) と,テストB受検者の能力値 \( \theta^B_i\)を推定します。
解の不定性から,共通受検者の能力値には以下の関係があります。\(k, l\) は等化係数と呼ばれます。
共通受検者の能力値の平均と分散の関係は次のようになります。
この式を \(k, l\) について解き,推定された能力値を代入すれば,\(k, l\) の推定値 \(\hat{k}, \hat{l}\) を得ることができます。
この \( k, l \) の値を使って,テストAの項目パラメタ,テストA受検者の能力値を,テストB上の値に変換します。そうすることにより,テストBの項目パラメタや能力値と相互比較できるようになります。
共通項目法
下図のように,共通の項目を含むテストCとテストDを作成し,異なる集団でテストを実施します。このようなデータ収集計画を共通項目デザインと言います。
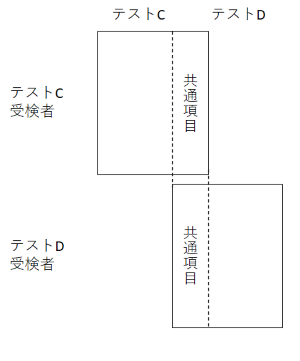
テストCデータを用いて,テストC項目の項目パラメタ \(b^C_j, a^C_j\) と,テストC受検者の能力値 \( \theta^C_i \),テストDデータを用いて,テストD項目の項目パラメタ \(b^D_j, a^D_j\) と,テストD受検者の能力値 \( \theta^D_i\)を推定します。
解の不定性から,共通項目の項目パラメタには以下の関係があります。\(k, l\) は等化係数と呼ばれます。
共通項目の困難度パラメタの平均と分散の関係は次のようになります。
この式を \(k, l\) について解き,パラメタの推定値を代入すれば,\(k, l\) の推定値 \(\hat{k}, \hat{l}\) を得ることができます。
これらの等化係数の推定値を用いて,テストCの項目パラメタやテストC受検者の能力値を,テストD上の値に変換します。そうすることにより,テストDの項目パラメタや能力値と相互比較できるようになります。
この方法は困難度パラメタの平均と標準偏差に基づいて等化を行うことから,Mean-Sigma法と呼ばれます。共通項目法には他にも,Mean-Mean法,Haebara法,Stocking-Lord法などの方法があります。
同時尺度調整法
下図のように,共通の項目を含むテストCとテストDについて,当該テストに含まれない項目のデータを欠測値としたデータを作成し結合します。
結合したデータを用いて,全項目の項目パラメタ,全受検者の能力値を推定します。そうすることにより,相互比較可能な項目パラメタ,能力値の値を得ることができます。
共通項目を変えながら3つ以上のテストを等化することも可能で,同時に複数のテストを実施したときなどに有効な手法です。
固定項目法
下図のように,共通の項目を含むテストCとテストDを作成し,異なる集団でテストを実施します。
テストCデータを用いて,テストCの項目パラメタと,テストC受検者の能力値の値を推定します。そして,テストDデータと,テストCで推定した共通項目の項目パラメタを用いて (固定して),テストDのみの項目の項目パラメタと,テストD受検者の能力値を推定します。そうすることにより,テストDの項目パラメタや能力値と相互比較できるようになります。
共通項目を変えながら3つ以上のテストを等化することも可能で,テストを継続的に実施していく場合などに有効な手法です。
項目反応理論を用いた等化・尺度化は,各項目の困難度や識別力が分かっていればスムーズですが,そのためには求められる要件のところで説明した厳しい条件を満たす必要があります。また,共通項目を用いる場合は,共通項目の困難度や識別力に偏りがないこと,極端な外れ値がないことが求められます。共通項目の数は,できれば30項目以上,短いテストでも20%以上は必要と言われることがあります。
<先頭へ戻る> <テスト研究のページへ戻る>