テストの評価
テストをより良いものにしていくためには,テストそのものを評価し改善する必要があります。テストや性格検査で測定される学力や能力,性格などは,構成概念と言われるもので,直接測ることができず,間接的に測定します。構成概念を間接的に測定するテストや性格検査の性質を評価する観点として,古典的テスト理論における測定の妥当性・信頼性があります。ここでは,構成概念,古典的テスト理論,妥当性,信頼性について説明します。
構成概念
構成概念とは
性格,感情,能力,学力などは,頭の中で考えた心理的なものであり,構成概念 (または心理的構成概念) と言われます。構成概念は,それを用いると何らかの現象を上手 (コンパクト) に説明することができる便利なものです。例えば,「優しい」人や「怖い」人と言えば,細かいことは分からないまでも,大まかなイメージを相手に伝えることができるでしょう。また,「コミュニケション力」や「国語力」などの単語からも,それがどのような能力を意味しようとしているか,何となく想像できます。 (想像の不一致が議論を巻き起こすことも多くあります。)
構成概念は頭の中で考えた抽象的な概念であり,物理的に存在するものではありません。よって,物差しや秤などを使って大きさや強さを直接測定することはできません。にもかかわらず,私達は普段から「あの人は周囲からの人望が厚い」とか「共感性が高まった」などと言っています。つまり,物理的に存在しない構成概念についても,その程度を何らかの方法で測定しているのです。私達は構成概念をどのように測定しているのでしょうか?
構成概念の測定
構成概念を測定しているとき,私達は,構成概念の程度が,思考・行動・言動・知識・成果物などに現れていると暗黙に仮定しています。そして,それらを観測したり,テストや心理尺度などに対する応答をみることによって,構成概念の程度を間接的に測定しています。
構成概念の測定のイメージを図で表すと次のようになります。
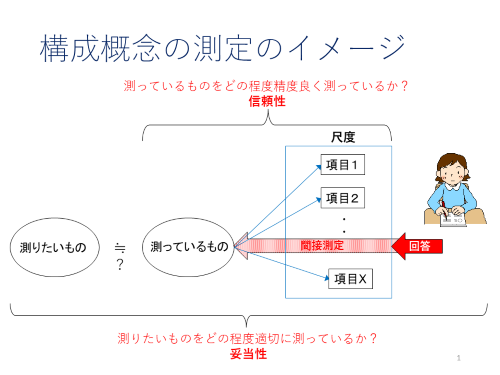
例えば,国語力を測るとしたら,国語力が高い人は解ける問題,国語力が低い人は解けない問題を複数提示し,それらの問題に対する応答 (解答) を採点することによって,国語力の程度を捉えようとします。ここで実際に観測しているのは問題に対する応答です。しかし,テストで測りたいものは「そのテスト問題(だけ)に答えられる力」ではなく,そのテスト問題に答えられるような,より一般的な国語力でしょう。それを直接測っている訳ではありません。もっと言えば,問題を通して間接的に測っている国語力が,測りたい国語力であるかどうかも定かではないのです。
構成概念の測定では次のようなことも問題になります。まず,間接測定なので誤差が大きいということです。例えば,時間をお腹の空き具合で計っているようなものですので,高い精度での測定は望めません。次に,観測値が0(ゼロ)でもその特性が無いとは限らないという問題があります。物理的なものの場合は,値が0であればその特性が無いことを意味しますが,国語のテストで0点を取ったからといって国語力が無い訳ではありません。さらに,何点取ったらどの程度の国語力があるということもはっきり言えませんし,「国語力」でイメージされることが人によって全く同じではないということも問題になります。
構成概念の測定で検討すべきこと
このように構成概念の測定は,直接測ることができず,思考・行動・言動・知識・成果物などを通して間接的に測定され,誤差が大きくなります。また,測っているものが測りたいものかどうかもはっきりしないという非常に曖昧な測定です。
こう聞くと,正確でないのならテストや性格検査は今すぐ止めるべきだという議論が出てきそうです。しかし,理想論や信条論ならそう言えるかもしれませんが,現実問題として,テストを全くなくしたらさまざまな困難を現場に与えてしまいます。入試ひとつ見てみても,個々の受験生の能力をテストを使わずに評価していたら,入試がいつまでたっても終わらなくなります。
「できないならやらなくていい」とは行かないなら,可能な限り正確に構成概念を測定することが求められます。そこで必要となってくるのが,測定の妥当性・信頼性の検討や項目分析です。測定の妥当性・信頼性はテストや心理尺度の品質を評価するものです。評価するだけでなく,できるだけ測定の妥当性・信頼性を高める努力をします。項目分析は,テストや心理尺度に含まれる個々の項目の性質を評価するものです。項目の性質を分析して,より良い問題を作成することに貢献します。
古典的テスト理論
テスト理論のうち,主として構成概念の測定の妥当性・信頼性を検討する理論を古典的テスト理論 (Classical Test Theory) と言います。古典的テスト理論は古い理論ということではなく,項目反応理論 (項目応答理論とも言う) に対する用語として用いられているものであり,現在でも多くのテストや心理尺度の開発に利用されています。
古典的テスト理論では,観測得点 \(X\) は,真の得点 \(T\) と誤差 \(E\) の和であると考えます。
ただし,真の得点 \(T\) は本当の得点という意味ではなく,同じ測定を繰り返したときの期待値であるとします。また,真の得点 \(T\) と誤差 \(E\) は無相関であると仮定します。
この測定モデルを基本モデルとして,古典的テスト理論では,測定の妥当性・信頼性を考えていきます。
妥当性
測定の妥当性
測定の妥当性とは,測定したい構成概念をどの程度適切に測定しているか,結果をどの程度合理的に解釈・運用しているかを表すもので,測定したい特性を捉えていると言える証拠の強さで評価されます。
しばしば「信頼性・妥当性が確認された尺度」などと言われますが,そうした言い方は本来誤りです。テストや尺度自体に妥当性が備わっているのではなく,妥当性は,それらを用いて行った評価や意思決定の結果が適切なものかどうかが問うものです。そこでは測定の妥当性という考え方をします。例えば,アメリカでは妥当性の高い歴史のテストでも,日本で実施すれば,少なくとも歴史のテストとしての妥当性は低くなるでしょう。
妥当性の確認
妥当性を確認する証拠として,伝統的に以下の区分が用いられています。
内容的妥当性(内容的証拠)
テストの内容がどの程度適切なものかを検討する概念で,専門家の目からみた適切さを考える論理的妥当性 (論理的証拠) や,回答者の目からみた適切さを考える表面的妥当性 (表面的証拠) があります。論理的妥当性は言わばお墨付きであり,表面的妥当性は,測定したい特性を発揮して回答してくれるかを確かめるものです。
内容的妥当性の問題点は,専門家や回答者の目からみた主観的な検討であり,客観性に劣ることです。
基準関連妥当性(基準関連的証拠)
客観的な外的基準値との関連を検討する概念で,テスト得点と基準値が同じ時点で得られる併存的妥当性 (併存的証拠),基準値が後で得られる予測的妥当性などがあります。多くの場合,テスト得点と基準値との相関係数で評価され,その値は妥当性係数と呼ばれることがあります。
基準関連妥当性の問題点は,外的基準の妥当性が問題になる場合があることです。
構成概念妥当性(構成概念的証拠)
測定したい構成概念に関する理論に対してテスト得点がどの程度適切な振る舞いをしているかを考える概念で,関連があるとされるものとの関係を検討する収束的妥当性 (収束的証拠) や,逆に関連がない (低い) とされるものとの関係を検討する弁別的的妥当性 (弁別的証拠) などがあります。
内容的妥当性も基準関連妥当性も,大きくは構成概念妥当性の枠組みで捉えることが可能です。
信頼性
測定の信頼性
測定の信頼性とは,測定している構成概念をどの程度精度良く (小さい誤差で) 測定しているかを表すもので,各回答者において回答が一貫している程度で評価されます。誤差が小さければ各回答者において測定値 (回答) は一貫するはずですから,各回答者における回答の一貫性の程度で信頼性の高低を評価することができます。測定誤差が小さく回答が一貫しているほど,信頼性の高い測定と言えます。
信頼性係数の定義
信頼性の程度を示す指標として,古典的テスト理論では信頼性係数を定義しています。古典的テストモデルをもう少し詳しくみてみましょう。
古典的テスト理論では,観測得点 \(X\) は,真の得点 \(T\) と誤差 \(E\) の和であると仮定します。
上でも述べたように,真の得点 \(T\) は本当の得点という意味ではなく,同じ測定を繰り返したときの期待値であるとします。誤差 \(E\) は,あて推量,記入ミスなど,真の得点 \(T\) とは関連なく観測得点に影響するもので,平均 0 とします。また,真の得点 \(T\) と誤差 \(E\) は無相関であると仮定します。
このように考えると,まず,観測得点 \(X\) の平均は,真の得点 \(T\) の平均に一致します。
また,観測得点 \(X\) の散らばり (分散) は,真の得点 \(T\) の散らばりと誤差 \(E\) の散らばりの和に分解することができます。
誤差が小さいほど誤差分散 \(\sigma_E^2 \) は小さくなりますので,信頼性係数 \(\rho_X^2\) を観測得点 \(X\) の分散に対する真の得点 \(T\) の分散の割合で定義します。
分散は 0 以上の値になりますから,信頼性係数 \(\rho_X^2\) は 0~1 の値を取り, 1 に近いほど信頼性が高い (誤差が小さい) ことを示します。
信頼性係数の推定
実際の測定においては,観測得点 \(X\) (データ) は入手可能ですが,真の得点 \(T\) や誤差 \(E\) のデータはありません。よって,定義式に従って信頼性係数の値を求めることはできず,何らかの方法で信頼性係数の値を推定する必要があります。回答の一貫性をどのように捉えるかにより,いくつかの推定法が考えられています。
再検査信頼性係数
同じ測定を2回繰り返したら同じ (ような) 結果になるだろうという再現性に着目して推定される信頼性係数を,再検査信頼性係数と言います。再検査信頼性係数は,同一集団に対して同じ測定を2回実施したときの,1回目のデータと2回目のデータの相関係数です。
測定を繰り返す時間間隔は,記憶が薄れ,かつ当該特性が変化しないと考えられる期間で,2週間~2ヵ月程度とするのが一般的です。
学力テストのように問題が公開され受検者が復習する場合は,1回目と2回目で同じ測定にはなりませんので,そのようなテストの信頼性係数の推定には向きません。
内的整合性信頼性係数 (α係数,アルファ係数)
同じ特性を測る各項目に対しては同じ (ような) 回答をするという回答の内的整合性に着目して推定される信頼性係数を,内的整合性信頼性係数と言い,多くの場合 \(\alpha \) (アルファ) 係数もしくはクロンバックの \(\alpha \) などとして報告されます。項目数を \(p\) ,各項目得点の分散を \(s_1^2, s_2^2,\dots,s_p^2\) ,合計得点の分散を \(s_X^2 \) とすると,\(\alpha \) 係数は次式で求められます。
\(\alpha \) 係数は 1 回の測定で推定できますので,単に信頼性係数を確認する場合や,特性が変化しやすい場合の信頼性係数の推定に適しています。
<先頭へ戻る> <テスト研究のページへ戻る>信頼性と妥当性の関係
妥当性は測りたい構成概念をどの程度適切に測っているかを表す性質,信頼性は測っている構成概念をどの程度精度良く測っているかを表す性質です。つまり,信頼性では何を測っているかは議論の対象ではなく,測っているものについての測定精度の高さだけを問題にします。これに対し妥当性は,測っているものが測りたいものであるかを検討します。
信頼性と妥当性の関係を図で表すと以下のようになります。以下,①~④の各状態についてみていきます。
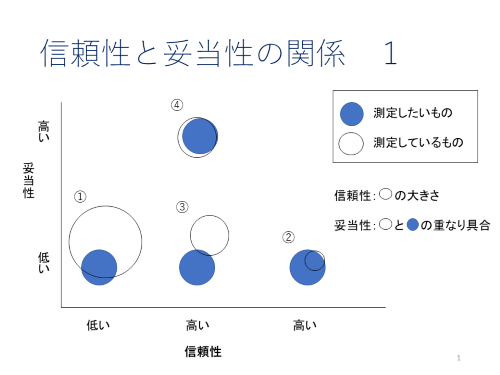
① 信頼性が低い ⇒ 妥当性は低い
信頼性が低ければ,測定誤差が大きくなるので,測りたいものを適切に測ることはできず,妥当性は低くなります。
② 信頼性が高すぎる ⇒ 妥当性は低い
信頼性が高すぎれば,測定している概念は狭いものになるので,測りたいものを適切に測ることはできず,妥当性は低くなります。
いわゆる「短縮版尺度」には注意が必要です。項目数が少なく信頼性が高いということは,ごく狭いことしか捉えていないということであり,妥当性が疑われます。心理尺度では多くの場合,5~10項目を使って1つの構成概念を測定し,妥当性を確保するようにしています。
③ 信頼性は適度に高いが的が外れている ⇒ 妥当性は低い
信頼性が高ければ何らかの構成概念を適切に測っていると考えられますが,それが測りたいものかは別の話であり,的が外れている場合は妥当性は低くなります。
④ 信頼性が適度に高く的を射ている ⇒ 妥当性は高い
信頼性が高ければ何らかの構成概念を適切に測っており,それが測りたいものであれば,妥当性の高い測定となります。
これらの検討や,構成概念測定のイメージ図からも分かる通り,信頼性は妥当性の必要条件 (一部) であって,十分条件ではありません。信頼性も,妥当性を確認する証拠の1つということになります。
信頼性が低い ⇒ 妥当性が低い
妥当性が高い ⇒ 信頼性が高い